Da ich in letzter Zeit immer öfter auch SSAS Tabular Modelle erstelle, habe ich mich vom Chefentwickler des AnalyticsCreators überzeugen lassen, den SSAS Generator für Tabular Modelle zu evaluieren. Tabular-Modelle sind technisch einfacher aufgebaut, als multidimensionale Modelle. Ein Tabular-Modell besteht aus Tabellen, die miteinander verbunden sind. Die Verbindung kann ein- oder zweiseitig sein. Es gibt Measures mit ein paar Eigenschaften, und das lässt sich recht gut automatisieren. Also habe ich ab September 2019 einige SSAS Tabular Modelle mit dem AnalyticsCreator erstellt und war positiv beeindruckt.
SSAS multidimensional vs Tabular
Unter dem gleichen Oberbegriff SSAS (SQL Server Analysis Services) vereint Microsoft zwei unterschiedliche Technologien
-
multidimensionale Datenbanken und
-
tabellarische Datenbanken. Das kann (und soll?) verwirren, da es sich um unterschiedliche Technologien handelt.
Die informative Dokumentation von Microsoft dazu: Vergleichen von tabellarischen und mehrdimensionalen Lösungen
Und noch ein paar subjektive Anmerkungen:
Mit den multidimensionalen Datenbanken arbeite ich seit 1999, damals noch "OLAP Services 7.0", ab 2000 "MSAS" (Microsoft Analysis Services), ab 2005 gab es mit "SSAS" (SQL Server Analysis Services) wieder eine neue Technologie, welche grundsätzlich der heutigen mehrdimensionalen Technologie entspricht. Typische Begriffe dieser multidimensionalen Technologie sind Würfel (Cubes) und Dimensionen. Ich bin ein sehr guter Experte für diese mehrdimensionalen Modelle.
Seit SQL Server 2012 gibt es zusätzlich SSAS Tabular, eine auf Tabellen basierende Technologie, wie sie auch in Power Pivot und Power BI verwendet wird.
Die Tabular Technologie wird von Microsoft sehr gepusht, für die sehr ausgereifte multidimensionale Technologie gibt es in letzter Zeit kaum Änderungen. SSAS Tabular hat sehr viele Stärken und wird sehr gut von Power BI unterstützt, welches intern auch diese Technologie verwendet. Die Unterstützung von Power BI für multidimensionale Datenbanken ist mangelhaft, vielleicht, um diese Technologie langsam sterben zu lassen. Allerdings gibt es sehr viele Stärken der multidimensionalen Technologie, welche sich mit der tabularischen Technologie (noch) nicht umsetzen lassen.
Ich setze aktuell auf beide Technologien:
Was sich mit Tabular sinnvoll realisieren lässt, wird pragmatisch mit Tabular gemacht, für alles andere gibt es weiter die multidimensionale Technologie.
Die Abfragesprache MDX kann für beide Technologien verwendet werden, DAX ist die Sprache für SSAS Tabular.
Warum ich den AnalyticsCreator nicht für die Erstellung multidimensionaler Modelle verwende
Nun zum AnalyticsCreator: SSAS Modelle kann man mit ihm erstellen, seit ich ihn kenne. Allerdings hatte ich das nur kurz ausprobiert und dann sein gelassen. Es ist wie mit anderen Tools, die multidimensionale Datenmodelle erstellen können: einige wichtige Funktionen sind möglich, einfach Modelle kann man also damit erstellen, allerdings holt man mich als Spezialisten wohl eher nicht für die einfachen und trivialen Modelle. So verwende ich oft m:n-Beziehungen, Measure-Expressions, diverse Berechnungen und Einstellungen. Und wenn ein Automatisierungstool das alles abbilden will, dann müsste es gleich den Funktionsumfang des Visual Studios für SSAS haben. Selbst, wenn ich den Kern eines Modells automatisch erstelle, würde ich dann doch sehr schnell auf manuelles Modellieren umsteigen (müssen).
Da gibt es zwar schöne Tools, mit denen man direkt aus einer MindMap ein OLAP-Modell mit einer relationalen Datenbank darunter erstellen kann, sehr schön für einen Prototypen in einem Workshop: von pmOne "oneMind", was dann "cMORE/Modeller" wurde. Allerdings findet man das aktuell nicht mal mehr auf ihrer Homepage, sondern nur noch Artikel darüber. Es hat sich eben doch nicht so durchgesetzt. Den "Bissantz Modeler" gibt es wohl noch: wie viele Versionen von dem Tool habe ich als Bissantz-Partner auf Bitte von Bissantz getestet und konnte doch nie so recht überzeugt werden.
AnalyticsCreator zur Modellierung von SSAS Tabular Modellen
Bis vor kurzem war die Verwendung des AC zur Erstellung von SSAS-Tabular-Modellen allerdings noch nicht massentauglich, es gab zu viele Dinge, die beachtet werden mussten, zu viele Fallen: das Modell konnte sich unbeabsichtigt ändern, wenn sich Beziehungen (AC-Relations) in den Quellen geändert hatten oder wenn FriendlyName geändert wurden. Das lag an der Grundidee der Realisierung:
-
FriendlyName bestimmten die Namen von Tabellen und Spalten (das ist auch heute noch so)
Anfangs hatte mich das verwirrt, nach kurzer Zeit fand ich diesen Ansatz ganz gut. Allerdings muss man aufpassen bei bestehenden Modellen, die bereits in Berichten verwendet werden, solche Berichte können dann unbrauchbar werden.
Mein normaler Weg in multidimensionalen Datenmodellen ist die Verwendung von "Translations" unter Beibehaltung der Original-Spaltennamen auch im OLAP-Modell. Wie anfällig die Verwendung von FriendlyName ist, muss sich zeigen. Solange es noch keine Berichte gibt, sind FriendlyName ein gutes Werkzeug, die Namen von Spalten und davon abgeleiteten Attributen zu definieren.
"Übersetzungen" werden zwar auch von SSAS Tabular unterstützt, allerdings ist das hier meiner Meinung nach aufwändiger, als in multidimensionalen Modellen. -
"AC-Relations" zwischen Objekten wurden zu Dimensionsbeziehungen. Und dabei musste man oft viele AC-Relations deaktivieren, damit aus überschüssigen AC-Beziehungen keine SSAS-Beziehung wurden, und wenn dann wieder neue AC-Relations von irgendwo vererbt wurden, hatte man wieder zu viele potentielle Dimensionsbeziehungen, das Modell konnte nicht erstellt werden usw.
Das war grauenvoll und der Hauptgrund, warum diese alleinige Methode meiner Meinung nicht massentauglich war. -
der Name einer Dimensionen (im Sinne einer verknüpften Tabelle) wurde nicht durch den FriendlyName der Transformation, sondern durch den FriendlyName der verknüpften Spalten definiert. So konnten aus einer Sicht im Datamart verschiedene Dimensionen mit unterschiedlichen Namen werden, wenn die verknüpften Spalten unterschiedliche Namen hatten. Und eine gemeinsame Dimension wurde es dann, wenn die FriendlyName der verknüpften Spalten gleich waren. In der Theorie eine brauchbare Idee, in der Praxis führte das zu Problemen.
-
Measures wurden in einem separaten Block als XMLA Skript definiert
Das alles hat funktioniert, war allerdings fragil.
Im Dezember 2019 wurde für Anfang 2020 ein verbesserter SSAS Generator versprochen, der dann auch nach und nach kam.
Inzwischen liegt ein sehr brauchbarer SSAS-Generator vor, gelegentlich gibt es Bugs, diese kann man im (nicht mehr existierenden) AC-Bugtracker eintragen, und sie werden schneller oder langsamer behoben.
Datamart-Transformationen als Basis der SSAS-Modellierung
Eine SSAS Modellierung erfolgt exklusiv über Datamart-Transformationen - spezielle AC-Transformationen, die sich von anderen AC-Transformationen unterscheiden. Ich erstelle für jedes SSAS-Modell ein eigenes Schema. Nach diesem Schema kann ich beim AC-Deployment filtern.
Hier sehen wir ein Datamart, die Pfeile zwischen den Transformationen entsprechen Tabellen-Beziehungen:
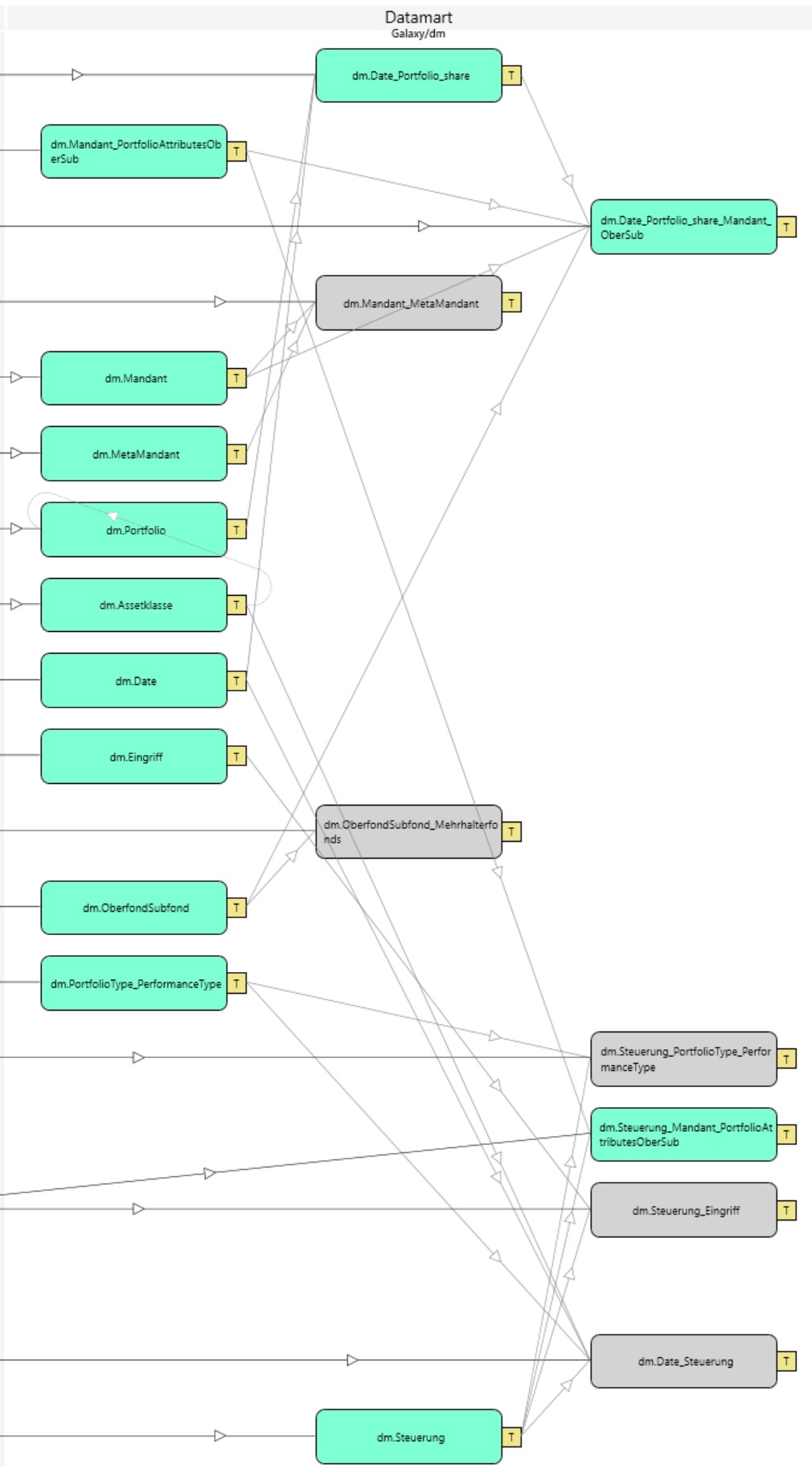
Leider kann man aktuell im Diagramm nicht erkennen, ob es ein- oder zweiseitige Beziehungen sind. Ein paar Feature-Request dazu gibt es:
-
h0000478: Datamart: verbesserte Anzeige von Referenzen im "normalen" Diagram
-
h0000498: Diagram - zweiseitige SSAS-Verbindungen anders anzeigen, als einseitige
Definition von SSAS-Tabellen
Die Steuerung, welche Tabellen wie im SSAS Modell erscheinen, erfolgt über die Tabellen-Eigenschaften einer Datamart-Transformation.
Wenn ein FriendlyName festgelegt wurde, dann wird dieser für den Namen der Tabelle verwendet, ansonsten der Table Name.
Auf der rechten Seite gibt es weitere wichtige Einstellungen:
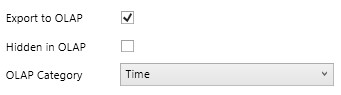
-
"Export to OLAP"
legt fest, ob die Tabelle überhaupt in das SSAS Modell übernommen wird. Standard ist "aktiv" -
"Hidden in OLAP"
legt fest, ob die Tabelle im SSAS unsichtbar ist oder nicht. Standard ist "nicht aktiv", die Tabelle wird also angezeigt -
"OLAP Category"
mit einer Auswahlbox. Es ist beispielsweise sinnvoll, eine Zeit-Dimension als "Time" zu markieren, da diese Eigenschaft von verschiedenen Frontend berücksichtigt wird.
Definition von SSAS-Tabellen-Attributen (Spalten)
Die Steuerung erfolgt ebenfalls über die Tabellen-Eigenschaften einer Datamart-Transformation, im Reiter "Columns".
Wichtige Spalten mit Einfluss auf das SSAS Modell:
-
FriendlyName
legt den Namen der Spalte fest, wenn leer, dann wird der "Column name" verwendet -
In OLAP
Auswahl-Liste mit den Ausprägungen-
Transfer (Standard, Spalte wird übernommen und angezeigt)
-
invisible (Spalte wird übernommen, aber nicht angezeigt)
-
not transfer (Spalte wird nicht übernommen)
-
-
Default Aggregate
wichtig bei der Verwendung von Power BI als Frontend, um zu steuern, ob und welche Standard-Aggregationen Power BI dem Anwender anbietet. -
DisplayFolder
wichtig, Ordnung in die Anzeige von Spalten und Measures zu bringen.
";" zur Auflistung von DisplayFoldern sollte auch möglich sein, um eine Spalte in verschiedenen Displayfoldern gleichzeitig anzuzeigen -
Formatstring
-
DataCategory
-
Description
werden in das SSAS Modell übernommen, Zeilenumbrüche werden ebenfalls übernommen, aber leider nicht von allen Frontends dargestellt (Insbesondere PowerBI entfernt leider Zeilenumbrüche) -
Spalten zur Definition von Tabellenbeziehungen (s. u.)
-
Referenced column
-
OLAP Reference
-
2-sided
-
Im Unterschied zu älteren Implementierungen der SSAS-Modellierung im AC hat jetzt jede Tabelle im SSAS-Modell eine eigene Quell-Transformation. Dadurch wird die Modellierung sehr viel übersichtlicher und robuster. Aus der Quelle einer Datamart-Transformation können schon immer sehr einfach verschiedene Datamart-Transformationen gleichzeitig erzeugt werden.
Die neue Methode ist verständlicher und das Modell besser zu überprüfen, als die Erstellung von mehreren SSAS Tabellen aus der gleichen Datamart-Transformation und die Steuerung über den FriendlyName der verknüpften Spalten, wie das früher der Fall war.
Definition von SSAS-Measures
Die Steuerung erfolgt nun ebenfalls über die Tabellen-Eigenschaften einer Datamart-Transformation, im Reiter "Measures". Auf meine Anregung kann man da auch Platzhalter verwenden.
Im folgenden Bild sehen wir die Verwendung von Platzhalten {ColumnName} {AggregationName} für den Namen der Measures, wobei das der von mir definierte Standard ist, den man als Parameter im AnalyticsCreator festlegen kann:
MEASURE_DEFAULT_NAME
Default measure name pattern
Default value:
{AggregationName} of {ColumnName} ({TableName})
Mein Custom value:
{ColumnName} {AggregationName}
Mir ist der Default Value entschieden zu lang. Ich riskiere es lieber, dass ich versehentlich gleichnamige Measures definiere, was dann natürlich zu einem Fehler führt, denn Spalten und Measures müssen modell-übergreifend eindeutig sein. Bei Bedarf verwende ich als optionalen Prefix eine Abkürzung des Tabellen-Namen.
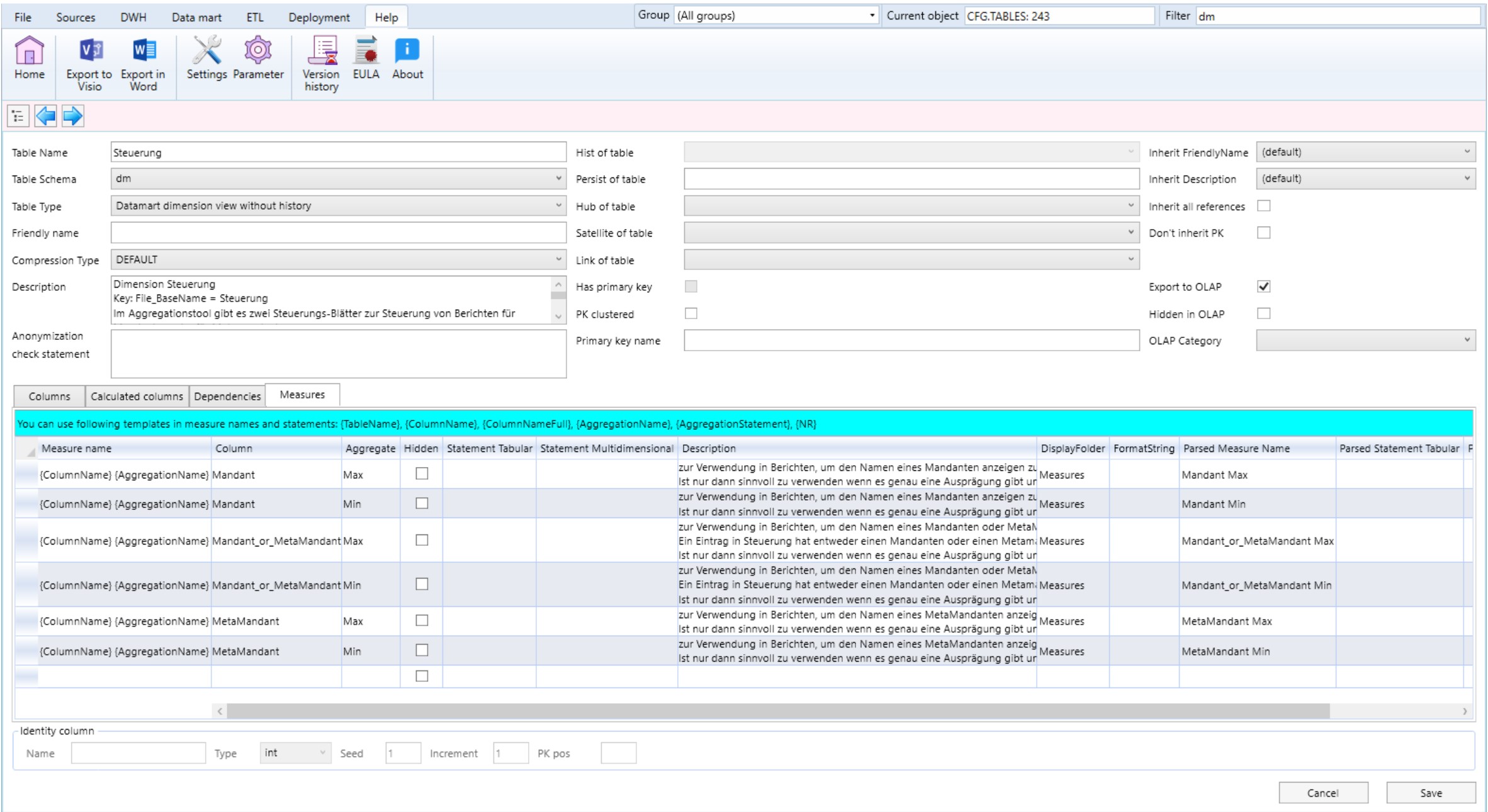
Es ist somit sehr einfach, Standard-Measures mit Standard-Aggregationen zu erstellen.
Natürlich können auch aufwendigere Measures definiert werden. Hier sehen wir einfache Divisionen. Zeilenumbrüche werden unterstützt, in den Formeln und in den Beschreibungen. Formatstring und DisplayFolder können zugeordnet werden. Auch die Zuordnung zu mehreren Displayfoldern gleichzeitig ist möglich, wenn ein ";" verwendet wird:
Measures\MW;Measures\Average (Date)
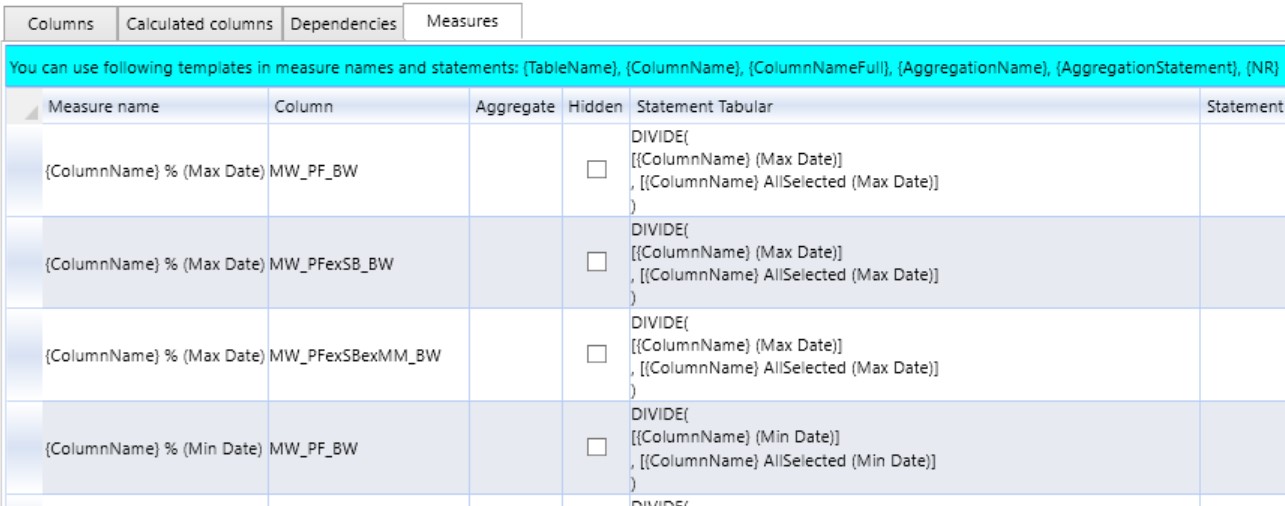
Mit den Measures funktioniert das ganz gut. Wenn man Platzhalter verwendet, passen sich auch die Namen der Measures an die neuen FriendlyName an. Was aber auch zu Problemen führen kann, wenn man mit festen Namen in Formeln arbeitet. Folgende Formel ohne Platzhalter funktioniert nur, solange der Name der Quell-Measure [MW PF_PW daily] gleich bleibt:
CALCULATE (
AVERAGEX ( VALUES ( 'Date'[Date] ), [MW PF_PW daily] ),
FILTER ( ALLSELECTED ( 'Date' ), TRUE( ) )
)Definition von Tabellen-Beziehungen
Für mich gehören die Begriffe Dimension und Measuregruppen (= Faktentabellen) eher in den multidimensionalen Bereich, wo klar zwischen diesen unterschieden werden muss. Bei der Tabular-Modellierung könnte man ebenfalls die Funktion auf Fakten-Tabellen für Measures und Dimensionstabellen für Attribute, nach den gefiltert werden soll, aufteilen. Muss man aber nicht. Und so haben bei mir klassische Dimensionstabellen auch Measures, beispielsweise
{TableName} count = COUNTROWS('{TableName}')
oder auch einige DistinctCount Measures.
Und Tabellen, die die Basis für diverse Measures sind, enthalten auch schon mal sichtbare Spalten, nach denen gefiltert werden kann.
Aus Performance-Gründen kann eine Aufteilung gelegentlich dennoch sinnvoller sein, als die Verwendung einer gemeinsamen Tabelle für Dimensions-Attribute und Measures.
1:1 Beziehungen können auch modelliert werden, allerdings implizit: Wenn eine Tabelle zwischen den PK-Spalten zweier Tabellen erstellt wird, dann wird daraus (auf meinem Implementierungswunsch hin) eine 1:1 Beziehung.
Die Definition von Tabellen-Beziehungen wurde im März 2020 wesentlich verbessert!
Basis von Tabellen-Beziehungen sind immer noch Referenzen.
Im SSAS Tabular können jeweils zwei Tabellen nur über eine Spalte verbunden werden. Da es m:n Beziehungen nur in neueren SSAS Versionen gibt (Und der AC das aktuell auch nicht unterstützt), sind in älteren Versionen nur 1:1 und 1:n Beziehungen möglich. Auf der "1"-Seite muss die verknüpfte Spalte der PK (Primary Key, Primärschlüssel) der Tabelle sein.
Ich verwende sehr gerne die Eigenschaft "Referenced Column" einer Tabellen-Spalte, weil diese nur mit einer anderen Tabelle über deren PK-Spalte verbunden werden kann, und auch nur dann, wenn es einen PK gibt und wenn der PK aus genau einer Spalte besteht.
Die Verwendung von "Referenced Column" ist aber nicht zwingend nötig, man kann auch einfach eine Referenz definieren. Dabei muss man dann aber selbst darauf achten, dass obige Bedingungen erfüllt werden.
Um nun tatsächlich eine Tabellen-Beziehung herzustellen, ist eine Referenz zwar notwendig, aber nicht ausreichend. Ob aus einer Referenz tatsächlich eine Beziehung wird, wird über die Eigenschaft einer Spalte auf der "n"-Seite einer 1:n-Beziehung festgelegt:
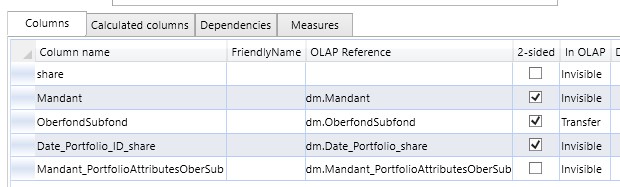
-
mit der Eigenschaft "OLAP Reference" wird über eine Auswahlliste festgelegt, mit welcher (Dimensions)-Tabelle die Verbindung hergestellt werden soll
-
über "2-sided" wird festgelegt, ob es sich um eine ein- oder ein zweiseitige Verbindung handeln soll
Es ist auch sehr wichtig, die PK der Datamart-Transformationen zu überprüfen und korrekt einzustellen:
-
Wenn der PK aus genau einer Spalte besteht, dann wird diese Spalte zum eindeutigen Row-Identifier der Tabelle und muss dann auch tasächlich beim Verarbeiten des SSAS Modells unique sein, sonst kommt es zu einem Verarbeitungsfehler
-
Wenn der PK aus mehreren Spalten besteht, dann bekommt die SSAS Tabelle keinen eindeutigen Row-Identifier
-
Wenn man keinen PK definiert, dann kann es passieren, dass dieser dann doch noch ungewollt oder unabsichtlich aus der Quelle der Datamart-Transformation vererbt wird. Es ist also besser und sicherer, eine PK-Definition zu haben.
zusätzliche XMLA Scripte
Wenn die oben beschriebenen Möglichkeiten nicht ausreichen, können weitere zusätzliche XMLA hinzugefügt werden unter:
-
Main Menu
-
Datamart
-
Button "Stars"
-
Auswahl des entsprechenden Datamart (= Schema) per Doppelklick
-
Bereich MDX, Reiter "Tabular"
Das war übrigens der Ort, an welchem früher Nicht-Standard-Aggregation-Measures per Skript definiert werden mussten. Und das ist am aktuellen Ort unter den Tabellen-Eigenschaften sehr viel besser gelöst.
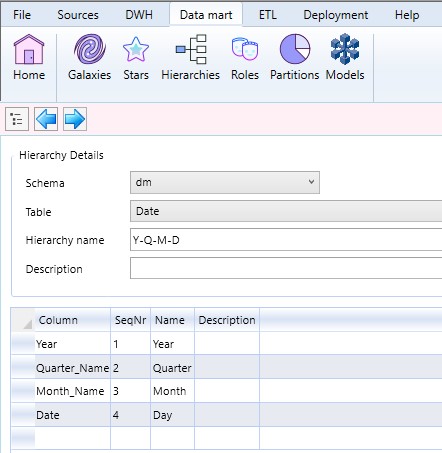
Hierarchien
Natürlich können auch Hierarchien definiert werden:
-
Main Menu
-
Datamart
-
Button "Hierarchies"
-
Auswahl des entsprechenden Hierarchie per Doppelklick
Partitionen
Die Definition von Partitionen erfolgt im Baum unter "Partitions" und ist intuitiv und selbsterklärend.
Perspektiven
Es soll auch möglich sein, Perspektiven zu erstellen. Vielleicht verrät mir der AC-Chefentwickler irgendwann einmal, wie und wo das definiert wird. Bisher ignoriert er meine mehrfache diesbezügliche Frage. Wenn ich eine Antwort bekomme, gibt es hier ein Update :-)
Vom AC-Deployment zur SSAS Tabular-Datenbank
AC-Deployment
Ich verwende getrennte AC-Deployments für
-
die Erstellung von DACPAC (falls ich solche benötige, weil es keinen Zugriff auf das Zielsystem mit Visual Studio gibt)
-
die Erstellung von SSIS Projekten
-
die Erstellung von XMLA-Skripten für SSAS Tabluar Modelle
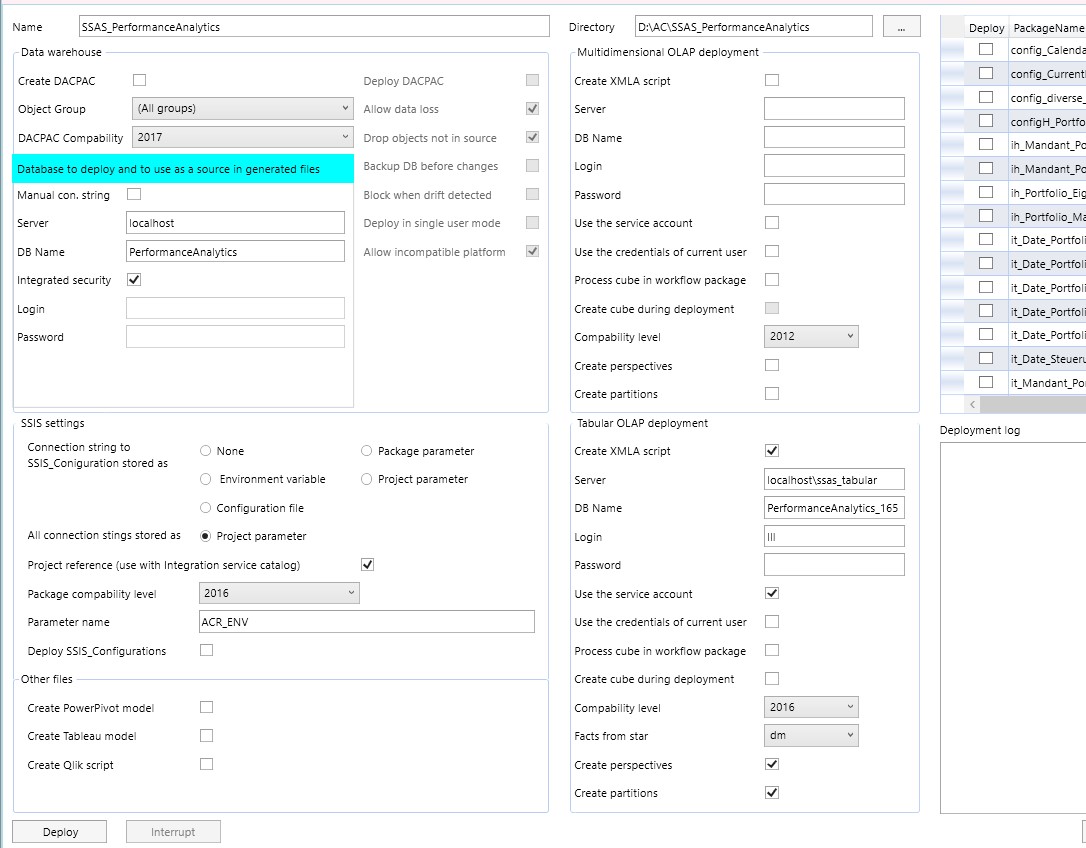
In den Deployments für SSAS Tabular XMLA-Skripte sind alle SSIS Pakete deaktiviert (rechts oben, mit einem Klick auf die Spalte "Deploy" kann die Auswahl invertiert werden, so können schnell alle Pakete ein- oder ausgeschlossen werden)
"Deploy SSIS_Configurations" sollte auch deaktiviert werden, damit der AC gar nicht erst versucht, sich mit dem unter "Server" eingetragenen Server zu verbinden. Wenn es den nicht gibt, dann dauert alles länger, es kommen Verbindungsfehler usw.
Name des Deployment
So heißt auch das erstellte VS-Projekt. Da dieses von mir aber nicht als Projekt verwendet wird, weil ich den Model-Namen nicht im AC konfigurieren kann, ist der Name egal.
Block Data warehouse:
Server und DB Name werden in die Connection-Properties des SSAS-Modells übernommen.
Block Tabular OLAP deployment
-
Create XMLA script
muss aktiviert werden -
Server
bei mir unwichtig:
wird nur dann verwendet, wenn die Optionen "Process cube in workflow package" oder "Create cube during deployment" aktiv sind -
DB Name
der Name des zu erstellenden SSAS Modells im XMLA Skript, ich nummeriere fortlaufend, damit es ein gleichnamiges Modell auf der Tabular-Instanz noch nicht gibt, wenn ich das XMLA-Skript ausführe -
Login, Password, Use the service account
wirkt sich auf die Connection-Properties aus -
Compatibility-Level
möglichst eine Version ab 2016 verwenden (Compatibility Level 1200):-
da ab dieser Version die XMLA Skripte nicht als XML sondern als JSON erstellt werden
-
die Erstellung wesentlich schneller erfolgt
-
es wichtige Features (insbesondere zweiseitige Verbindungen zwischen Tabellen) erst ab dieser Version gibt
-
-
Facts from star
wird bei mir immer auf genau einen Star (= Schema) eingeschränkt! -
Create Partitions, Create Perspectives
SQL Server Standard-Edition unterstützt weder Partitionen noch Perspektiven, also muss man das ausschalten können
offener Feature-Request:
-
0000438: SSAS Tabular Generator - Möglichkeit, den Namen des Modells zu bestimmen
Wenn ich die Möglichkeit hätte, das erstellte Modell "Model" zu nennen, was der Standard-Name im SSAS ist (ob das sinnvoll ist oder nicht, ist eine andere Frage), dann könnte ich das vom AC erstellte XMLA-Skript jetzt so verwenden, wie es ist. Leider hat das vom AC erstellte Modell einen anderen Namen (den des Deployments?).
XMLA-Skript im SSMS ausführen
Ich verwende im AC den recht neuen Parameter DEPLOYMENT_CREATE_SUBDIRECTORY und setze diesen auf 0:
Create subdirectory for every createted deployment package. 0-no (all files in output directory will be deleted), 1-yes. Default - 1
Somit bleibt der Dateiname des erstellten XMLA-Skriptes immer gleich, das Skript kann im SSMS geöffnet bleiben, auch wenn ein neues Skript erstellt wird, SSMS erkennt das und fragt, ob die Datei neu geladen werden soll. Somit kann man sehr einfach hintereinander kleine Modifikationen im AC vornehmen, ein neues Skript erstellen und das Skript dann ausführen.
Hier erklärt sich auch, warum ich für meine Modelle eine fortlaufende Nummer verwende, da vom AC Create-Scripte erstellt werden, kann damit ein bestehendes Modell gleichen Namens nicht überschrieben werden. Ich kann so ein neues Modell bereitstellen, ohne zuvor ein bestehendes Modell unter dem gleichen Namen löschen zu müssen. Vielleicht könnte man mal ein Feature-Request erstellen, dass ein Create-oder-Update XMLA-Skript erstellt wird.
Es könnte nun beim Ausführen des XMLA-Skriptes zu Fehlern kommen, weil Pfade zwischen Tabellen nicht eindeutig sind, oder weil Measure-Definitionen nicht korrekt sind. Diese Fehler müssen iterativ beseitigt werden, bis sich das XMLA-Skript formal fehlerfrei erstellen lässt. Die Fehler beim Ausführen des XMLA-Skripts sind normalerweise aussagekräftig genug.
SSAS-Tabular VS-Projekt erstellen
Auch, wenn man das XMLA-Skript formal fehlerfrei ausführen kann, könnte es inhaltlich falsch sein.
Wenn man sich das erstellte Modell auch optisch ansehen will, wenn man es unter Versions-Kontrolle verwalten will oder aus welchen Gründen auch immer: Man kann und sollte nun aus dem SSAS-Modell, das es auf dem Server gibt, ein SSAS-Tabular VS-Projekt erstellen.
Dazu wählt man im Visual Studio "Create a new project", als Projekt-Typ "Import from Server (Tabular)", vergibt im nächsten Schritt einen Namen und legt ein Verzeichnis fest:
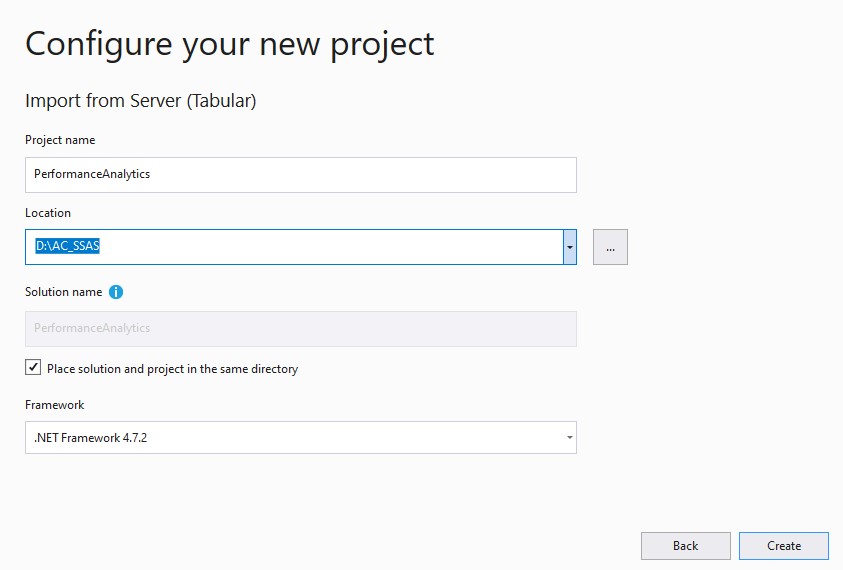
Ich verwende immer den gleichen Namen und das gleiche Verzeichnis. Ältere Versionen in diesem Verzeichnis benenne ich um oder lösche sie.
Dann auswählen, ob der integrated Workspace oder ein konkreter Server verwendet werden sollen (ich nehme integrated Workspace), im nächsten Schritt das zu importierende Modell angeben (Server Name bei mir: ".\tabular" oder "localhost\tabular", Database Name: aus Auswahlliste das eben erstellte auswählen). OK, und das SSAS-Projekt wird erstellt.
Dieses kann man sich nun anschauen: ob die Beziehungen optisch korrekt aussehen usw.
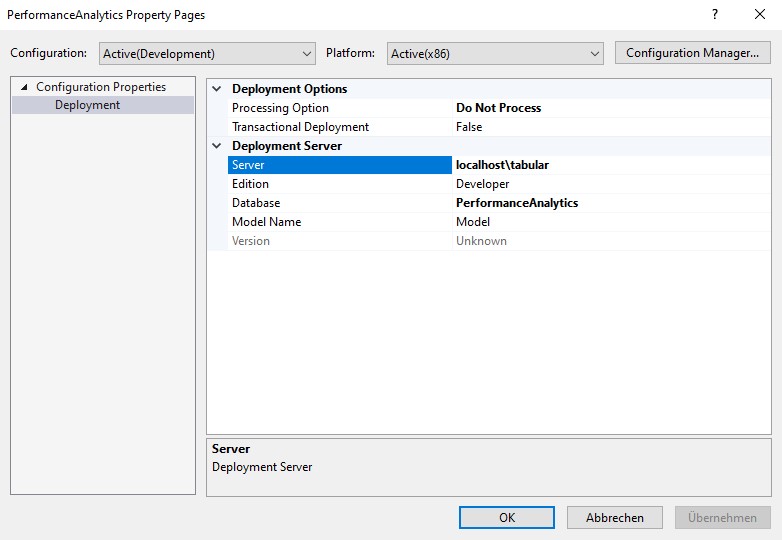
Nun in den Eigenschaften des Projekts einstellen, wie es bereitgestellt werden soll. Hier wird mir als Standard Model Name nun "Model" vorgeschlagen.
Wie man im Screenshot sieht, wähle ich normalerweise die Option "nur bereitstellen, nicht verarbeiten". Das liegt auch an VS-Bugs: wenn es beim Deployment einen Verarbeitungsfehler gibt und man das Fenster verlässt, kann es sehr schwer werden, das Fenster wieder zu finden, um es zu schließen. Man muss dann VS im Taskmanager abschießen.
Dann das Projekt bereitstellen.
finales XMLA mit SSMS erstellen
-
Im SSMS kann man sich nun mit dem SSAS Modell auf dem Server verbinden und über das Kontext-Menü das benötigte finale XMLA-Skript erstellen.
-
Man könnte auch im vom AC erstellten XMLA-Script per Suchen und ersetzten den Modell-Namen ändern.
-
Man könnte auch den vom AC erstellten Modell-Namen verwenden.
Ich gehe den Zwischenschritt über die Erstellung eines SSAS-Projekts auch aus Gründen der Qualitätskontrolle, weil ich die Tabellen-Beziehungen optisch sehen will. Nur so fällt mir auf:
-
ob unerwartet Beziehungen dazugekommen sind, was passieren kann, wenn neue Beziehungen in das DM-Schema vererbt werden und der AC daraus erst einmal automatisch neue SSAS-Beziehungen erstellt
-
ob unerwartet bestehende Beziehungen verschwunden sind, was auch passiert, und wofür ich dann im Bugtracker neue Einträge anlege.